非監督式學習指的是利用沒有標註正確答案的資料,找到它們彼此之間的模式與關係。針對不同的情境可以分為:
1. 聚類(Clustering)
2. 關聯規則(Association Rule)
3. 降維(Dimensionality Reduction)
巴黎奧運正如火如荼的進行中,也感謝中華隊的運動員們為國爭光,今天我們進行一個與運動用品相關的實作。假設我們在一家運動用品店工作,老闆希望重新規劃商場的運動用品區域,以增加顧客的購買可能性。我們已經有顧客的消費記錄資料,透過這些資料,我們就可以進行購物籃分析,以觀察消費者在購買商品時,商品之間是否有關聯性。這將幫助我們了解哪些商品經常一起購買,進而優化商品的陳列,提高銷售額。
程式碼如下:
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# 生成假資料
products = ['羽毛球拍', '籃球', '高爾夫球桿', '拳擊手套', '衝浪板', '空氣手槍', '排球']
np.random.seed(0)
data = [np.random.choice(products, np.random.randint(1, len(products)), replace=False) for _ in range(10000)]
df = pd.DataFrame(data)
# One-hot encoding
one_hot = pd.get_dummies(df.stack()).groupby(level=0).sum()
# 使用Apriori演算法進行購物籃分析
frequent_itemsets = apriori(one_hot, min_support=0.1, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
# 輸出結果
print(frequent_itemsets)
print(rules)
1. 資料生成
products = ['羽毛球拍', '籃球', '高爾夫球桿', '拳擊手套', '衝浪板', '空氣手槍', '排球']
np.random.seed(0)
data = [np.random.choice(products, np.random.randint(1, len(products)), replace=False) for _ in range(10000)]
df = pd.DataFrame(data)
np.random.seed() 可以確保每次生成的資料是一樣的。np.random.choice() 隨機選擇產品組合,生成10000筆資料,每筆資料的產品數量隨機分配2. One-hot encoding
one_hot = pd.get_dummies(df.stack()).groupby(level=0).sum()
stack() 將資料做格式轉換,把每筆資料的產品項目展開成一列pd.get_dummies()將每筆資料的產品進行編碼(0:沒購買,1:有購買)groupby(level=0).sum() 將每筆資料的產品編碼結果合併成一個One-hot列表3. 使用Apriori演算法進行購物籃分析
frequent_itemsets = apriori(one_hot, min_support=0.1, use_colnames=True)
apriori() 進行購物籃分析,最小支持度設定為0.1,即商品組合出現比例至少10%4. 生成關聯規則
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
association_rules() 生成關聯規則,設定評估指標為lift,並將最小閾值設為1(lift值要大於等於1)5. 輸出結果
print(frequent_itemsets)
print(rules)
建立的假資料如下: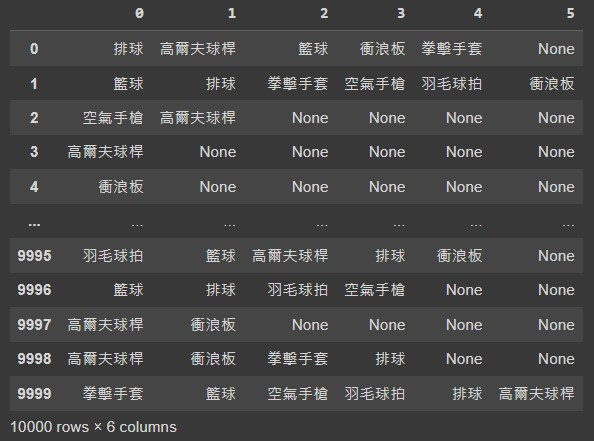
One-hot encoding結果如下: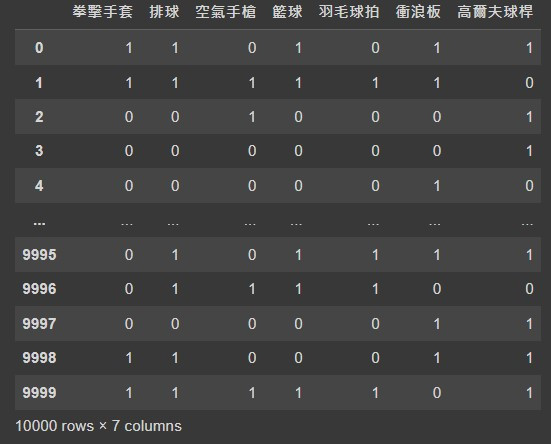
Apriori演算法進行購物籃分析結果如下: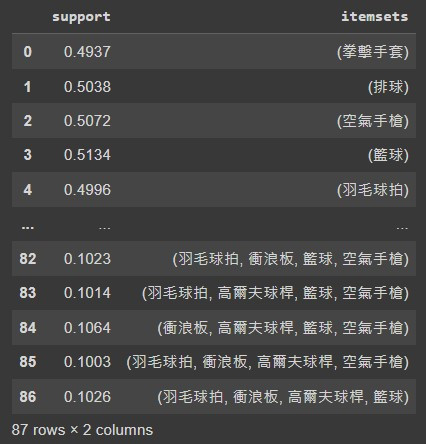
support 表示每個itemsets在所有資料裡面出現頻率關聯規則如下: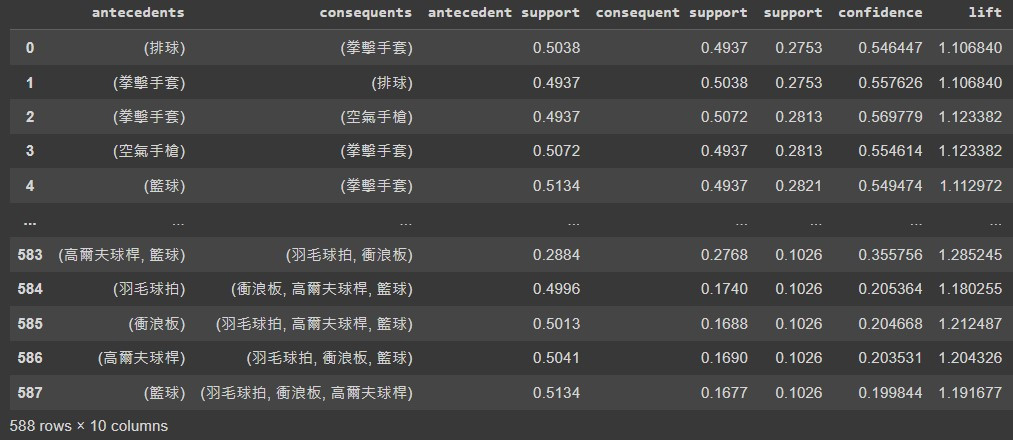
confidence表示購買antecedents後有多少機率會購買consequentslift 是用來衡量商品的相關性,lift值越高說明產品之間的相關性越強,1表示沒有相關;大於1正相關;小於1負相關購物車分析適用於很多不同的情境,不管是電商還是實體商店都能透過這樣的關聯規則來做商業分析和策略規劃。
今天放假沒有去上班,追了20集的「藍色監獄」,只能說劇情很好猜測但是裡面想傳達的概念可以套用在很多情境中(雖然這是一部足球動漫,但我完全把它套用在籃球情境上哈哈)。這周的目標是想找個寧靜的時間看完「青春18x2」,聽說風評很好,我個人十分期待哈哈。
今天是父親節(付清節)㊗️全天下的88們父親節快樂🎉

